searchly


![]()





🎶 Song similarity search API based on lyrics
This API is no longer deployed for its public usage. Run your own deployment for using it.
Contents
Motivation
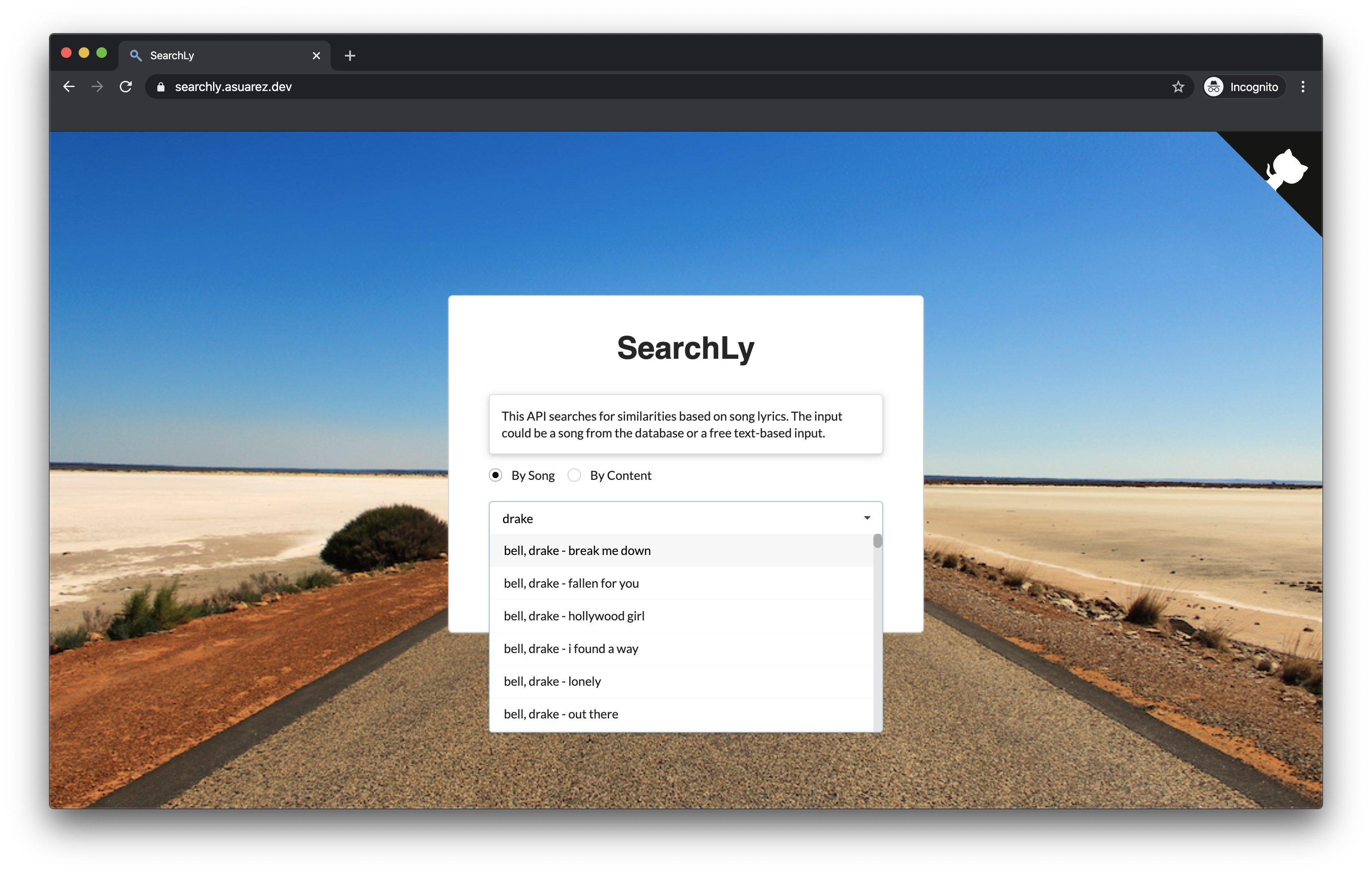
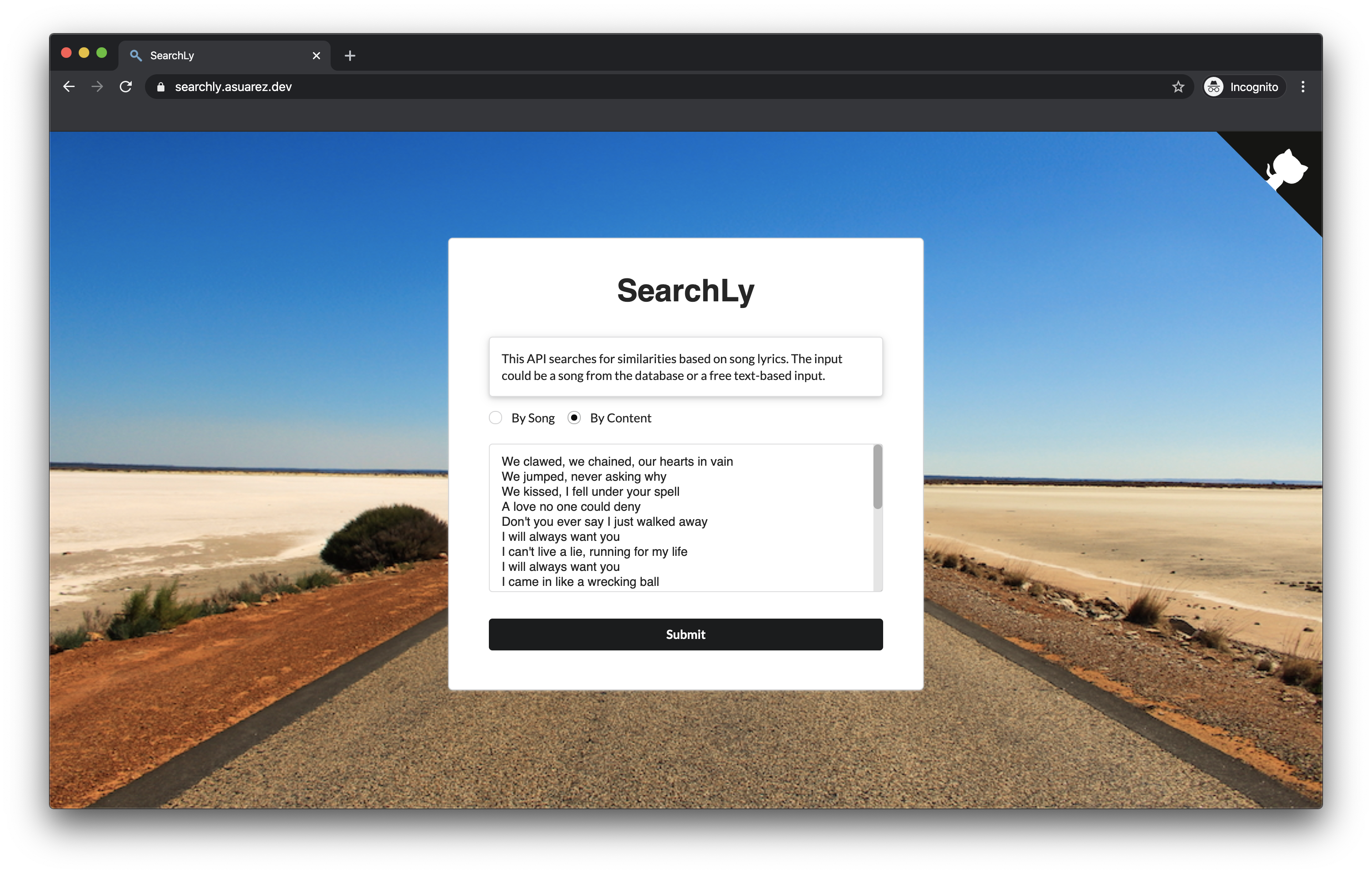
This project was built in order to create an API for searching similarities based on song lyrics. There are a lot of songs in the industry and most of them are talking about the same topic. What I wanted to prove with SearchLy was to estimate how similar are two songs between them based on the meaning of their lyrics.
SearchLy is using a database of 150k songs from AZLyrics, using this scraper, which is being updated periodically. Then, using word2vec and NMSLIB, it was possible to create an index where you can search similarities using the k-nearest neighbors (KNN) algorithm. For having a visual image of this index, check the visualization NMSLIB tool.
The API is available here along with its documentation. Test it on this website demo.
Note: I am currently using a micro-instance from DigitalOcean where the API is deployed, so you should expect a bad performance. However, if this API becomes popular I will deploy it in a bigger instance.
Requirements
- Python 3.7+
- docker-ce (as provided by docker package repos)
- docker-compose (as provided by PyPI)
Recommendations
Usage of virtualenv is recommended for package library / runtime isolation.
Usage
To run the API, please execute the following commands from the root directory:
-
Setup virtual environment
-
Install dependencies
pip3 install -r requirements.lock -
Initialize database (if is not initialized)
source db/deploy.sh -
Run the server as a docker container with docker-compose
docker-compose up -d --buildor as a Python module (after enabling the Development mode)
python3 -m src.searchly
Run tests
-
Run Searchly locally with the Development mode enabled.
-
Run tests
python3 -m unittest discover -v
Development
Development mode
Edit src/searchly/__init__.py and switch DEVELOPMENT_MODE flag from False to True for enabling development mode.
# DEVELOPMENT_MODE = False
DEVELOPMENT_MODE = True
Logging
For checking the logs of the whole stack in real time, the following command is recommend it:
docker-compose logs -f
Scripts
The module src/searchly/scripts contains a bunch of scripts whose allow to create and build the needed index for searching the similarity between song lyrics. It’s needed to have the Development mode enabled for using the scripts.
- Fill database (
fill_database.py): from a zip file extracted from the AZLyrics scraper, found on this repository, fills the database with all the data on it. - Train (
train.py): given the data of the database, extracts all the features from the song lyrics and trains a word2vec model. The results will be saved on thedatafolder. - Build (
build.py): given the trained word2vec model, builds an NMSLIB index for allowing searchs on the API. The index file will be saved on thedatafolder. - Extract maximum distance (
extract_maximum_distance.py): given the trained word2vec model and the built index, searchs across all the database for getting the maximum distance between two points. This is needed for computing the percentage of similarity instead of returning a raw distance on the API response. The result will be saved on thedatafolder.
How to add a new test
Create a new Python file called test_*.py in test.searchly with the following structure:
import unittest
class NewTest(unittest.TestCase):
def test_v0(self):
expected = 5
result = 2 + 3
self.assertEqual(expected, result)
# ...
if __name__ == '__main__':
unittest.main()
Authors
License
MIT © SearchLy